
Deformación dinámica del objeto por contacto. Este documento ha sido elaborado por los siguientes profesores e investigadores del campo gráfico relacionado con el aprendizaje automático; Cristian Romero, Dan Casas y Miguel A. Otaduy, los tres de la Universidad Rey Juan Carlos en España; y un cuarto profesor; Maurizio M. Chiaramonte de Meta Reality Labs Research en USA.
Presentan un método basado en el aprendizaje artificial para dar vida propia a una simulación deformable del subespacio; obteniendo una deformación detallada que se activa directamente por el contacto. Estas deformaciones obtienen mejores resultados que los que podemos ver en otras aplicaciones; ya que de lo que se trata es de que el objeto interactúe por sí mismo con el resto de objetos que tiene alrededor.
Esto nos permite reducir significativamente el muestreo de configuraciones del objeto deformable y, posteriormente, aprender para llevar a cabo deformaciones cada vez más complejas. Para esta simulación en tiempo real del modelo MANO con dinámica, utilizamos solo una pose de la mano para el entrenamiento. Observemos las deformaciones precisas de alta resolución debido al contacto con un objeto rígido, resaltadas en los zoom.
Proponemos un método novedoso para aprender sobre las deformaciones de contacto no lineales altamente detalladas para la simulación dinámica en tiempo real. Nos apartamos de estrategias previas de aprendizaje de deformación y modelamos las deformaciones de contacto de una manera centrada en el contacto.
Un sistema que ofrece muy buenos resultados
Esta estrategia muestra una excelente generalización con respecto al espacio de configuración del objeto, y permite un aprendizaje simple y preciso. Complementamos la estrategia de aprendizaje centrada en el contacto con dos ingredientes clave adicionales; aprender un campo vectorial continuo de deformaciones de contacto, en lugar de una aproximación discreta; y la comprobación del mapeo entre la configuración del contacto y las deformaciones del contacto.
Estos dos ingredientes contribuyen aún más a la precisión, eficiencia y generalización del método. Integramos nuestro modelo de deformación de contacto basado en el aprendizaje con la dinámica del subespacio; mostrando simulaciones dinámicas en tiempo real con detalles finos de deformación de contacto.
Introducción a la deformación dinámica del objeto por contacto
La simulación de contacto y deformaciones ha atraído un gran interés en los gráficos por ordenador; ya que sirve para dar vida a modelos generados por ordenador de humanos y sus objetos circundantes. Sin embargo, uno de los desafíos restantes en el campo es simular el contacto de alta resolución a velocidades interactivas. Por ejemplo, para aplicaciones de realidad virtual.
En nuestro trabajo, buscamos aprovechar las metodologías de aprendizaje automático para modelar deformaciones impulsadas por contacto; inspiradas en su éxito en el modelado de deformaciones autodirigidas. Es decir, deformaciones que surgen en función del propio movimiento del objeto.
Estos métodos emplean una representación subespacial del objeto deformable, y luego aprenden deformaciones no lineales ricas en función del estado del subespacio. Algunos trabajos ya han intentado modelar deformaciones de contacto utilizando enfoques de aprendizaje automático. Pero solo modelan una respuesta de contacto global suave, o muestran interacciones 3D muy limitadas.
Planteamos la hipótesis de que existe una limitación fundamental en las estrategias de aprendizaje de deformación previas. Las deformaciones se modelan de una manera centrada en el objeto. Lo cual es una excelente opción para las deformaciones autodirigidas; ya que son suaves con respecto al estado del subespacio del objeto; y luego el aprendizaje automático logra una buena generalización incluso a partir de datos dispersos.

Deformaciones por contacto directo
Sin embargo, las deformaciones impulsadas por contacto no son suaves con respecto al estado del objeto; por lo tanto, el aprendizaje automático de estas deformaciones requeriría un muestreo denso del estado subespacial del objeto. Esto es difícil, ya que el espacio de configuración puede ser grande y difícil de cubrir.
Nos apartamos de las estrategias previas de aprendizaje de deformación y proponemos una estrategia centrada en el contacto; para aprender las deformaciones impulsadas por el contacto. Esta es también la intuición detrás de los pinceles de escultura en escultura digital; y similar al aprendizaje de deformaciones esqueléticas en coordenadas locales de partes del cuerpo.
Demostramos que nuestro enfoque centrado en el contacto muestra una excelente generalización con respecto al estado subespacial del objeto. Hasta solo 8 poses de entrenamiento para un ejemplo desafiante de pato con un estado subespacial de 87 dimensiones; o una pose para el ejemplo de mano en la figura teaser. Nuestro novedoso método, reúne tres componentes principales.
Primer componente principal
Como se ha descrito anteriormente, modelamos las deformaciones de contacto de una manera centrada en el contacto, es decir, en una referencia local del colisionador. Observamos que las deformaciones de contacto son más suaves cuando se modelan de manera centrada en el contacto; y esto contribuye a una mejor generalización y a un aprendizaje más fácil y preciso.
Segundo componente principal
Consideramos las deformaciones de contacto como un campo vectorial continuo. En lugar de aprender una aproximación discreta, aprendemos el campo continuo directamente, inspirados en trabajos recientes sobre modelado de superficies implícitas. Aprender el campo de deformación de contacto generaliza la continuidad y la diferencia a configuraciones invisibles.
Tercer componente principal
Analizamos el mapeo entre la configuración de contacto y las deformaciones de contacto resultantes. De esta manera, aprovechamos la localidad de las deformaciones de contacto y las aprendemos de manera efectiva a partir de datos escasos.

El uso de redes neuronales en el proyecto
Más adelante, haremos referencia a la aproximación de la red neuronal de nuestro modelo de deformación por contacto. También discutimos la generación eficiente de datos de entrenamiento. Discutimos la simulación de deformaciones dinámicas utilizando nuestro modelo de deformación de contacto basado en el aprendizaje. Aumentamos una deformación dinámica del subespacio con detalles casi estáticos impulsados por contacto que se expresan en el mismo subespacio. Lo que permite simulaciones que son rápidas y altamente detalladas.
Hemos aplicado nuestro método a simulaciones dinámicas en tiempo real sobre diferentes objetos deformables. Mostramos simulaciones subespaciales 2D y 3D generadas con las coordenadas biarmónicas generalizadas acotadas, y simulaciones 3D del modelo mano. Hemos aumentado estas deformaciones dinámicas del subespacio con deformaciones de contacto ricas y altamente detalladas, todo en tiempo real. Ejemplos y código están disponibles aquí, para ayudar en la reproducción de nuestro trabajo.
Deformación dinámica del objeto por contacto y aprendizaje
Hoy en día, el enfoque clásico para implementar formas 3D deformables es a través del skinning de mezcla lineal (LBS). Donde se utiliza un esqueleto subyacente para parametrizar la pose de un objeto articulado; y la mezcla lineal de transformaciones óseas individuales deforma la superficie de la forma.
Además de esto, es común utilizar un método de deformación del espacio de pose (PSD) para mitigar artefactos LBS bien conocidos. PSD agrega correctivos dependientes de la postura a la malla de plantilla de modo que la malla posada no exhiba deformaciones antinaturales.
Se han propuesto muchas obras para ampliar la DSP de múltiples maneras. Entre ellos, los más cercanos a nuestro trabajo son los métodos que aprenden los correctivos dependientes de la postura a partir de los datos. Para los humanos de cuerpo completo, SMPL aprende correctivos de postura y forma de un gran conjunto de datos de escaneos estáticos 4D.
Trabajos posteriores han aprovechado las posibilidades de aprendizaje de las redes neuronales para extender SMPL para modelar deformaciones dinámicas de tejidos blandos. Del mismo modo, utilizar múltiples redes neuronales para aproximarse a los componentes de deformación no lineal de la plataforma.
Cómo interactúa con manos y caras
Algunos trabajos también han aprendido correctivos para modelar partes específicas del cuerpo, como caras o manos. Más allá de los cuerpos humanos, las deformaciones de las prendas también se han aprendido de simulaciones, utilizando correctivos de forma o incluso características neuronales.
A pesar del realismo de las deformaciones mostradas por estos métodos, debido a su estrategia de deformación autodirigida es decir; las deformaciones dependen solo de la postura o el movimiento esquelético, no pueden modelar el contacto.
Nuestro trabajo también surge de la idea de agregar correcciones de aprendizaje, pero aportamos nuevos ingredientes para modelar deformaciones debido a interacciones externas. Una representación centrada en el contacto y un campo de deformación continua.
Simulación por contacto y subespacios
Agregamos deformaciones de contacto basadas en el aprendizaje a las simulaciones dinámicas del subespacio; por lo tanto, observamos cómo otros han diseñado simulaciones de subespacio para objetos deformables y cómo manejaron el contacto.
La reducción del orden del modelo asume que se da un objeto deformable de alta resolución; y encuentra un subespacio de baja dimensión que representa con precisión el rango de deformaciones del objeto. El análisis modal encuentra un buen subespacio basado en las propiedades mecánicas del objeto; y el análisis de componentes principales lo hace basándose en ejemplos de deformación.
Las derivadas modales pueden mejorar el subespacio lineal básico de estos dos enfoques; mientras que los autocodificadores pueden encontrar un subespacio no lineal latente a partir de datos. Recientemente, mejoraron las diferencias de los autocodificadores profundos para su uso en simulación deformable; y mostraron cómo hacer cumplir las leyes de conservación física en los subespacios aprendidos.
Otros enfoques de reducción de órdenes de modelo pueden trabajar con definiciones de subespacios impulsadas por artistas. Como marcos dispersos, mangos escasos, o plataformas de animación. El enfoque reciente utiliza el eje medio del objeto para encontrar un subespacio motivado por la geometría expresiva.
Trabajar en nuestro propio subespacio
Finalmente, algunos autores han buscado complementar los subespacios definidos por el artista con la reducción del orden del modelo para aumentarlos con dinámicas rápidas. Algunos ejemplos incluyen subespacios basados en pose, deformaciones locales de piel.
Un problema común con la reducción de pedidos del modelo es que las deformaciones de contacto no se resuelven con gran detalle. La variedad de deformaciones de contacto es demasiado grande para ser capturada por la base del subespacio, y las simulaciones resultantes parecen demasiado suaves.
Algunos trabajos han abordado esta limitación, enriqueciendo el subespacio con una base local o con una sub-malla local. Este último trabajo soporta deformaciones más generales que la nuestra, pero sufre una alta caída de rendimiento a medida que crece la influencia del contacto. Reportando velocidades de fotogramas por debajo de 1 frame por segundo.
Fotogramas a gran velocidad
Nuestro método mantiene una alta velocidad de fotogramas estable con decenas de frames por segundo; lo que lo hace adecuado para interactuar en tiempo real. Combinan el aprendizaje con la reducción de órdenes de modelos para producir deformaciones impulsadas por contacto. Su método logra producir deformaciones detalladas, pero requiere un muestreo denso del subespacio del objeto deformable.
Nuestro método centrado en el contacto supera esta limitación y generaliza bien bajo un muestreo escaso del subespacio; lo que lo hace adecuado para interacciones 3D más complejas. En más profundidad sobre el tema, más adelante discutimos las comparaciones con este método, que no generaliza bajo datos escasos.
El método de Holden utilizan el aprendizaje automático para modelar la actualización dinámica de objetos deformables por subespacio bajo contacto externo. Sin embargo, su enfoque no puede producir deformaciones de contacto detalladas. Ya que la representación del objeto deformable se limita a un subespacio lineal aprendido de ejemplos de deformación.
Campos basados en el aprendizaje
Nuestro enfoque centrado en el contacto se inspira en la tendencia reciente de aprender representaciones implícitas para codificar formas 3D. Los trabajos iniciales aprenden a aproximarse a la superficie de las mallas 3D prediciendo una ocupación binaria de puntos 3D arbitrarios.
Dado que se utilizan redes neuronales totalmente conectadas, la representación de aprendizaje es continua, eficiente en memoria y fácilmente diferenciable. Lo que aporta muchos beneficios en los marcos de simulación, visión por computadora y procesado de geometría.
Por ejemplo, estas representaciones permiten consultas diferenciables dentro y fuera, que son difíciles de implementar con representaciones tradicionales como mallas poligonales. Investigaciones de seguimiento demostraron que las redes neuronales también son capaces de aprender a distancia de la superficie. Que también es un bloque de construcción fundamental para muchos métodos en gráficos por ordenador.
Dicha codificación basada en el aprendizaje, a menudo denominada representaciones neuronales implícitas o campos de distancia neuronal; tienen el beneficio clave de no estar limitadas por una discretización explícita de la superficie de la forma; que es una característica fundamental para nuestro método.
Representación implícita y precalculada
Para entrenar estas representaciones, los métodos existentes a menudo requieren supervisión 3D directa; en forma de una representación implícita conocida o precalculada de la forma objetivo. Curiosamente, los métodos más recientes son capaces de entrenar directamente desde nubes de puntos en bruto; es decir, sin supervisión en el conjunto de nivel cero o superficies abiertas. Algo que no es posible con las representaciones tradicionales de campos de distancia firmados (SDF).
Más allá de las superficies rígidas, las ventajas que aportan las representaciones implícitas de aprendizaje se han aprovechado para modelar objetos más complejos; como las formas articuladas. El sistema Deng del año 2020 modela un cuerpo humano articulado utilizando una representación implícita por partes. Trabajos posteriores muestran modelos corporales totalmente paramétricos.
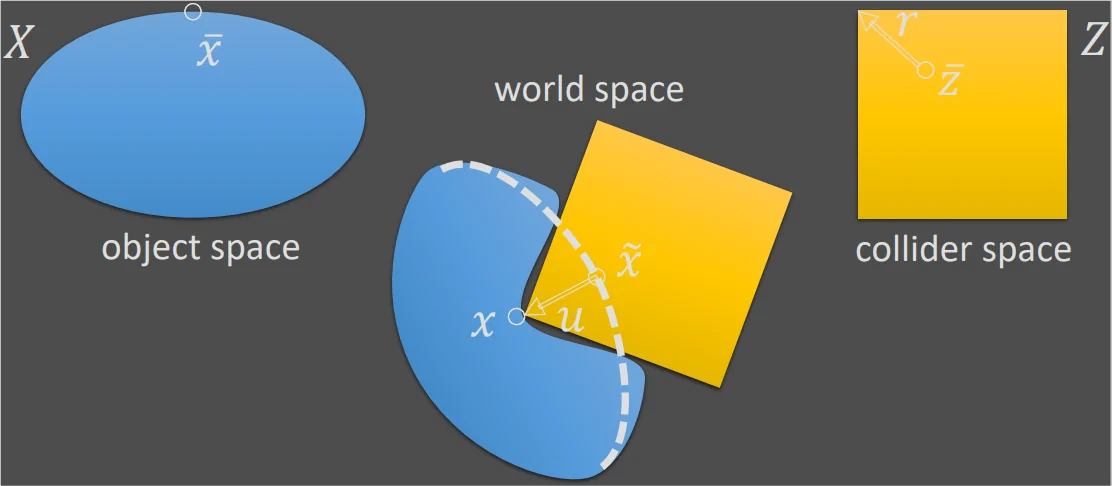
Cuando un colisionador Z toca un objeto deformable X, produce un campo de desplazamiento u(x ̄). Modelamos el campo de deformación completo x(x ̄); como la suma de una deformación dinámica del subespacio x ̃ (x ̄) y una aproximación basada en el aprendizaje del campo de desplazamiento de contacto u(x ̄). Una idea clave de nuestro método es aprender este campo como un desplazamiento r(z ̄) parametrizado en el espacio del colisionador.
Métodos generales en el campo del aprendizaje
Otros métodos exploran usos más generales de estos campos de aprendizaje y, más allá de usarlos para aproximarse a funciones implícitas; los aprovechan para expandir las propiedades de la superficie a puntos 3D. Esto está inspirado en los trabajos sin aprendizaje inteligente de Kim y Romero en el 2020. Que difunden pesos de cotejamiento superficial hacia adentro para articular cuerpos humanos volumétricos representados con tetraedros.
Los métodos posteriores basados en el aprendizaje expanden las propiedades de la superficie, como los pesos de movimiento, fuera de la superficie corporal. Esta estrategia se ha utilizado para registrar escaneos 3D en mallas, y para articular escaneos en bruto de humanos vestidos. El estudio de Santesteban del 2021 va un paso más allá y tiene algunos campos neuronales para difundir los correctivos de superficie de pose y forma a R3.
Los campos de aprendizaje se utilizan para proyectar prendas a una forma canónica. Lo que permite un manejo altamente eficiente de las colisiones cuerpo y prenda. También utilizamos campos de aprendizaje para modelar colisiones, pero nuestra formulación centrada en el contacto es más general. Permite el uso de colisionadores externos y se puede conectar a marcos dinámicos de deformación del subespacio.
Explorando el campo del aprendizaje
El alto potencial de las representaciones de campo de aprendizaje se ha identificado recientemente. Se ha extendido rápidamente para abordar muchos problemas diferentes en Visión por ordenador y Gráficos por ordenador, creados por Chen en el 2021.
Un ejemplo destacado son los campos de radiancia neuronal (NeRF). Que aprenden a sintetizar vistas novedosas de escenas complejas mediante la optimización de una función de escena volumétrica continua utilizando un conjunto escaso de vistas de entrada.
Otro ejemplo popular son los métodos que aprenden a reconstruir formas 3D a partir de imágenes; condicionando una representación implícita en características locales extraídas de imágenes. En nuestro trabajo, también aprovechamos este alto potencial y lo aplicamos a los campos de desplazamiento de contacto.
Deformaciones centradas en el contacto
En esta sección, describimos cómo modelamos las deformaciones impulsadas por contacto. Nuestro enfoque de modelado, es decir, la selección de representaciones de entrada y salida de deformaciones impulsadas por contacto, es clave para diseñar una aproximación efectiva basada en el aprendizaje.
Comenzamos la sección con una definición de la notación, así como una descripción de nuestros objetos deformables del subespacio. Luego, definimos los campos de desplazamiento del espacio del colisionador, como una representación suave de los campos de deformación producidos por el contacto.
Continuamos con una discusión de representaciones continuas versus discretas del campo de desplazamiento; y el impacto en el diseño de una aproximación basada en el aprendizaje. Para concluir, proponemos una aproximación escasa del campo de desplazamiento para mejorar aún más la capacidad de aprendizaje.
Definiciones
Aprendemos deformaciones centradas en el contacto en un objeto deformable del subespacio X. En ausencia de contacto; un punto en el espacio objeto (no deformado) x ̄ ∈ X se asigna a una posición deformada x ̃ en el espacio mundial a través de una deformación del subespacio.
En nuestro trabajo, mostramos diferentes modelos de deformación del subespacio que combinan una deformación dinámica del subespacio con correcciones casi estáticas basadas en el aprendizaje. También parametrizadas en el mismo subespacio.
Más específicamente, un ejemplo que mostramos es el uso de mangos combinados de puntos y marcos. Con un campo de deformación suave definido por coordenadas biarmónicas generalizadas acotadas (BGBC); y aumentado aún más con correcciones internas basadas en el aprendizaje.
Otro ejemplo que mostramos es el uso de esqueletos articulados dinámicos, con mezcla lineal de skinning; y correcciones paramétricas basadas en posturas, estudiado por Romero en el 2017. Denotamos como x la configuración cinemática del subespacio del objeto deformable X.
Objetos y fórmulas para cada necesidad
Consideremos también un objeto colisionador Z, y z ̄ ∈ Z un punto en el espacio del colisionador. En nuestro trabajo, nos limitamos a los colisionadores rígidos. Luego, denotamos como z la configuración rígida del colisionador Z.
Cuando el objeto deformable X toca un colisionador Z; aumentamos el campo de deformación del subespacio x ̃(x) con un campo de desplazamiento de contacto u(x ̄); que produce un campo de deformación total x(x ̄) = x ̃(x ̄) + u(x ̄), (1).
Como se muestra en la siguiente imagen. En nuestro trabajo, modelamos el subespacio deformation x ̃(x ̄) usando dinámica, y el desplazamiento de contacto u(x ̄) como una deformación casi estática. De esta manera, los objetos deformables exhiben una rica dinámica global combinada con detalles impulsados por el contacto.
Desplazamiento del colisionador en el espacio
Deseamos encontrar una parametrización adecuada del campo de desplazamiento de contacto u(x ̄); que permita una aproximación eficiente y precisa con una arquitectura basada en el aprendizaje. En el caso límite de una traslación de un colisionador a lo largo de un objeto plano, infinito y homogéneo. El campo de desplazamiento inducido por el contacto es constante cuando se expresa en el espacio del colisionador.
En casos más generales, el colisionador puede producir una deformación global sobre el objeto deformable. Pero lejos del colisionador esta deformación es bien capturada por la deformación del subespacio x ̃(x ̄); está cerca del colisionador donde el desplazamiento adicional u(x ̄) es relevante.
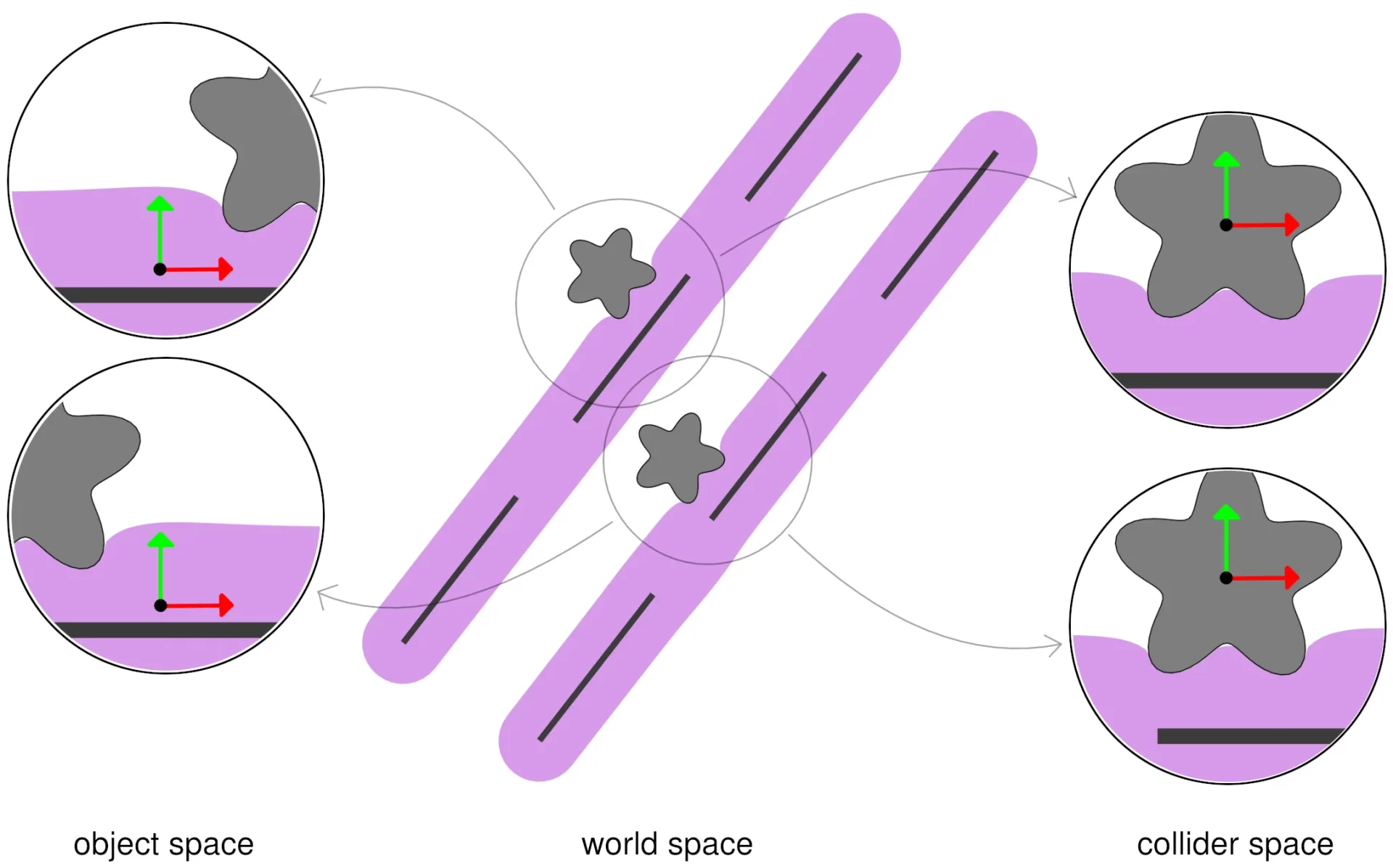
Observamos que, cuando el colisionador se mueve, este desplazamiento local impulsado por contacto varía más suavemente en el espacio del colisionador que en el espacio del objeto. Como se muestra en la imagen 3.
Desplazamiento de contacto parametrizado
Basándonos en esta intuición, elegimos parametrizar el desplazamiento de contacto en el espacio del colisionador, r (z ̄), como se muestra en la imagen 2. Luego, para evaluar el desplazamiento mundo-espacio; primero transformamos la deformación del subespacio x ̃(x ̄) en espacio colisionador; y luego transformamos el desplazamiento del colisionador-espacio nuevamente al espacio mundial. Con T(z)
En la imagen 3, vemos los primeros planos comparan la representación de los desplazamientos de contacto en el espacio de objetos x ̄ (izquierda). Versus el espacio del colisionador z ̄ (derecha) para estos dos ejemplos. A medida que el colisionador barre la superficie del objeto deformable; los desplazamientos de contacto del espacio del colisionador son notablemente más suaves. Esto afecta drásticamente la capacidad de aprendizaje de nuestro método.
Una transformación rígida basada en la configuración del colisionador; el desplazamiento se obtiene formalmente como: u(x ̄) = T(z) · r (z ̄), con z ̄ = T(z)−1 · x ̃(x ̄).
Desplazamiento del objeto 3D por contacto
El campo de desplazamiento de contacto depende de la configuración relativa entre el objeto deformable y el colisionador, que expresamos como T(z)−1 ·x. En la práctica, implementamos esto transformando todos los controladores de puntos y tramas del objeto deformable en el marco de referencia local del colisionador.
Sobre la base de esta configuración relativa; el campo de desplazamiento de contacto se puede definir mediante la siguiente función: r (z ̄) ≡ f z, ̄ T(z)−1 · x.
Aproximamos la función f utilizando el aprendizaje automático. Como hemos comentado anteriormente, f es en la práctica una función suave de la configuración relativa entre el colisionador y el objeto deformable. Métodos típicos de deformación basados en datos aprenden en cambio las deformaciones objeto-espacio T(x)−1 u(x ̄).
Sin embargo, hemos encontrado que el desplazamiento de contacto parametrizado en el espacio del objeto es mucho menos suave. Como consecuencia directa, la función de desplazamiento del espacio del colisionador
f se puede aprender utilizando muchos menos datos de entrenamiento y con una red más pequeña que una función de desplazamiento objeto-espacio.
Aprendizaje de un campo de desplazamiento de contacto
Para la simulación dinámica de la mecánica de contacto; el campo de deformación x(x ̄), y por lo tanto el desplazamiento de contacto u(x ̄), debe evaluarse en dos tipos de puntos. Un tipo son los puntos en la superficie del objeto deformable X, para el cálculo de potenciales de contacto o restricciones de contacto.
El otro tipo son los puntos dentro de X, para el cálculo de la energía interna y sus derivadas. Debido a la deformación del subespacio, en la práctica utilizamos puntos de curvatura en el segundo caso.
Ambos tipos de puntos de evaluación se fijan en el espacio de objetos x ̄. Por lo tanto, bajo una parametrización objeto-espacio de desplazamientos de contacto, resulta conveniente aprender directamente la representación discreta de esta función.
Además, un enfoque común en el aprendizaje automático es proyectar tales representaciones de alta dimensión en un subespacio lineal compacto utilizando PCA; y aprender solo un pequeño número de coeficientes PCA. Sin embargo, los puntos de evaluación no se fijan en el espacio del colisionador.
Muestrear el espacio del colisionador
Si bien podría ser posible muestrear el espacio del colisionador y aplicar el aprendizaje basado en PCA; los desplazamientos resultantes del espacio del colisionador deben interpolarse a los puntos de evaluación. En cambio, motivados por métodos recientes que aprenden campos continuos, optamos por aprender la función de desplazamiento de contacto f directamente como un campo vectorial.
Además, al aprender el campo f utilizando una red de perceptrón multicapa (MLP), el resultado es eficiente en memoria, continuo y totalmente diferenciable. Que son propiedades clave para una simulación dinámica de éxito. El desplazamiento u(x ̄) se define sólo dentro del objeto deformable X. Esto conduce a una discontinuidad en el muestreo del espacio del colisionador z ̄ al aprender la función f.
Sin embargo, el sesgo inductivo de la red MLP se generaliza suavemente a puntos invisibles en el espacio del colisionador z ̄. Que pueden consultarse en tiempo de ejecución. El cálculo de fuerzas y sus derivadas requiere la evaluación de gradientes con respecto al espacio del colisionador. Sin embargo, la diferenciación de la red proporciona una evaluación del gradiente por construcción.
Escarificación y propagación de la función de aprendizaje
El mayor desafío en el aprendizaje de la función de desplazamiento de contacto f es la dimensionalidad de la configuración x del objeto deformable. A primera vista, aplicar nuestras deformaciones centradas en el contacto a objetos con un rico subespacio subyacente x.
Es decir, con muchos grados de libertad en el subespacio que requiere una explosión de combinaciones de las configuraciones deformadas que deben alimentarse como datos de entrenamiento para aprender f. Y una función que es más compleja y más difícil de aprender.
Sin embargo, como se ha comentado anteriormente, podemos asumir con seguridad que los desplazamientos de contacto tienen soporte local. Ya que las deformaciones lejos del colisionador son más gruesas y están bien representadas por la deformación del subespacio subyacente.
Entonces, el desplazamiento de contacto en una ubicación del espacio de objetos 𝑥¯ solo está influenciado por la configuración x de los puntos de control cercanos de la deformación del subespacio. Ten en cuenta que, aunque la función de desplazamiento de contacto 𝑓 está parametrizada en el espacio colisionador 𝑧¯, implícitamente depende del espacio objeto 𝑥¯ a través de 𝑧¯ = T(z)−1 ·𝑥˜(𝑥¯).
La bienvenida opción de dispersar
Con base en las observaciones anteriores, aproximamos el campo de desplazamiento de contacto a través de una función dispersa; 𝑟 (𝑧¯) ≈ 𝑓 𝑧,¯ W(𝑥¯) · T(z)−1 · x. Donde W(𝑥¯) es una matriz de pesos dispersantes que varían espacialmente, es decir, muchas de sus filas son cero.
Aprovechamos la escasez de nuestros modelos de deformación del subespacio para definir los pesos de dispersión. Específicamente, con U(𝑥¯) la base del subespacio (por ejemplo, base BGBC o pesos de movimiento) en un punto material 𝑥¯, construimos los pesos como W(𝑥¯) = diag(U(𝑥¯)).
Ideas similares de pesos dispersos que varían espacialmente se han utilizado en otros contextos para obtener definiciones de pose locales. Por ejemplo, deformación ponderada del espacio de pose o pesos de atención de pose.
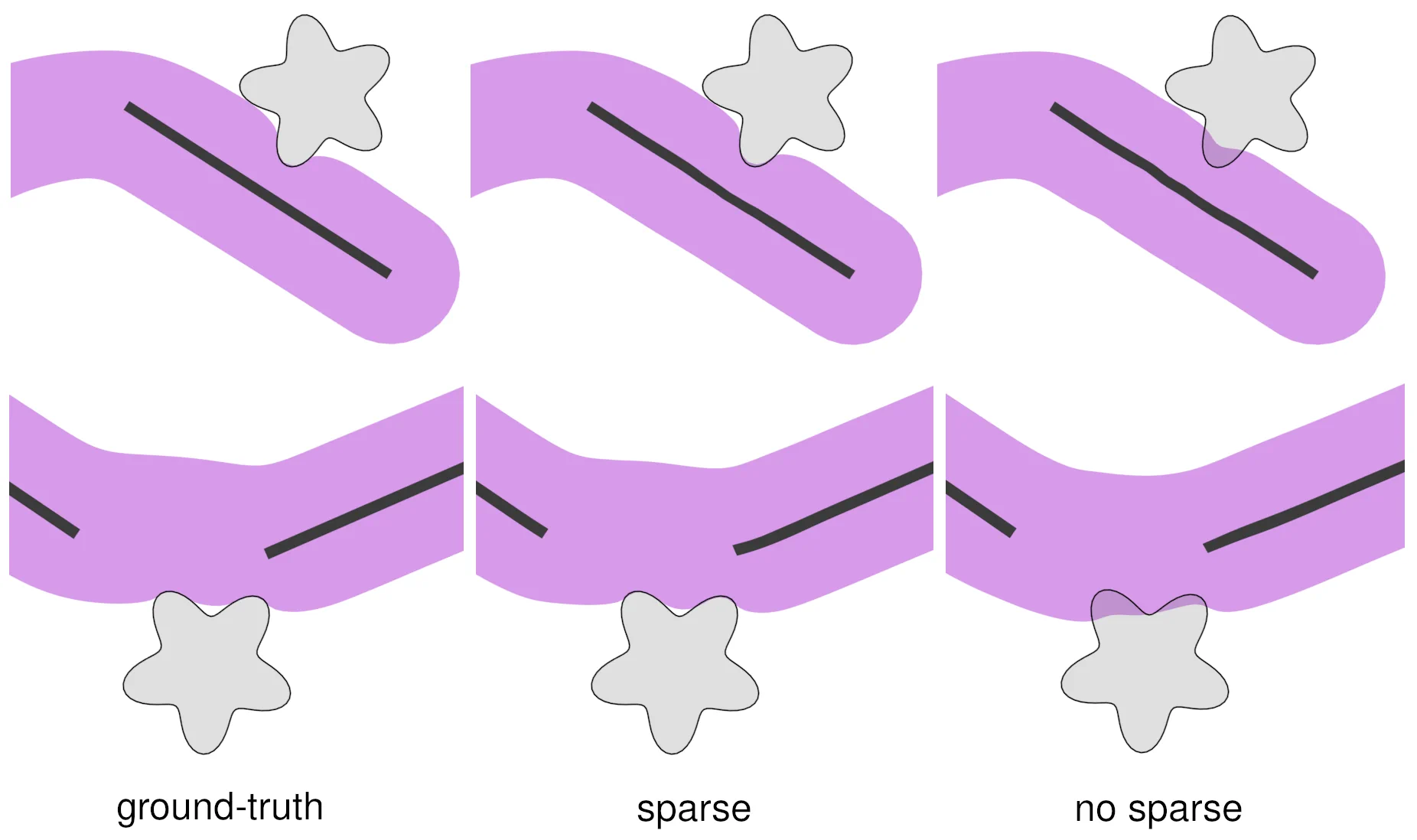
Representar desplazamientos
En la imagen 4, vemos dos ejemplos (arriba, abajo) para representar que los desplazamientos de contacto están dominados por la configuración de asas/huesos cercanos del objeto deformable. Aprovechamos esta observación diseñando una aproximación escasa de la función de desplazamiento de contacto.
Aquí, comparamos los desplazamientos reales en el terreno (izquierda), los desplazamientos aprendidos con pesos que dispersan. Con los mismos datos de entrenamiento, la función dispersar logra resultados superiores. Ya que logra eliminar la ambigüedad del estado del subespacio que contribuye a los desplazamientos de contacto.
La imagen 4 muestra un ejemplo que compara la precisión del aprendizaje con una función de aprendizaje escasa frente a una densa; y proporcionamos un análisis cuantitativo un poco más adelante.
Datos y aprendizaje de la deformación dinámica del objeto por contacto
Planteamos el problema de diseñar una aproximación basada en el aprendizaje de la función de desplazamiento de contacto 𝑓 en (4). Resolver este problema requiere abordar varias tareas, las cuales definen la estructura de esta sección.
Primero, abordamos el diseño y entrenamiento de una arquitectura de red neuronal para calcular la función de desplazamiento de contacto 𝑓. En segundo lugar, describimos nuestra estrategia para muestrear los argumentos de 𝑓. Es decir, el espacio del colisionador, 𝑧¯, y la configuración relativa entre el objeto y el colisionador, T(z)−1 · x. Para concluir, describimos la generación de desplazamientos de contacto de tierra-verdad 𝑟 (𝑧¯), que requiere resolver configuraciones de contacto con y sin desplazamientos de contacto.

Arquitectura de red neuronal en la deformación dinámica del objeto por contacto
Usamos un MLP de dos capas completamente conectado para modelar la función 𝑓, con h como función de activación. El tamaño real de cada capa depende del ejemplo específico. Nuestro enfoque de investigación se centra en el diseño de la función a aprender, no en la arquitectura de aprendizaje.
Sin embargo, al igual que otros trabajos que aprenden campos; investigamos el uso de las funciones de Fourier para mejorar la capacidad de aprendizaje de la red neuronal. Sin embargo, nuestros intentos iniciales no tuvieron éxito, ya que la generalización fuera de la región muestreada empeoró. Dejamos las optimizaciones de la arquitectura de la red neuronal como trabajo futuro.
Para conocer los parámetros de la red, definimos una función de pérdida que combina dos términos. Uno es el error L2 de los desplazamientos de contacto estimados frente a los desplazamientos de entrenamiento reales, sumados.
Mejoras en las posibilidades comparando con herramientas anteriores
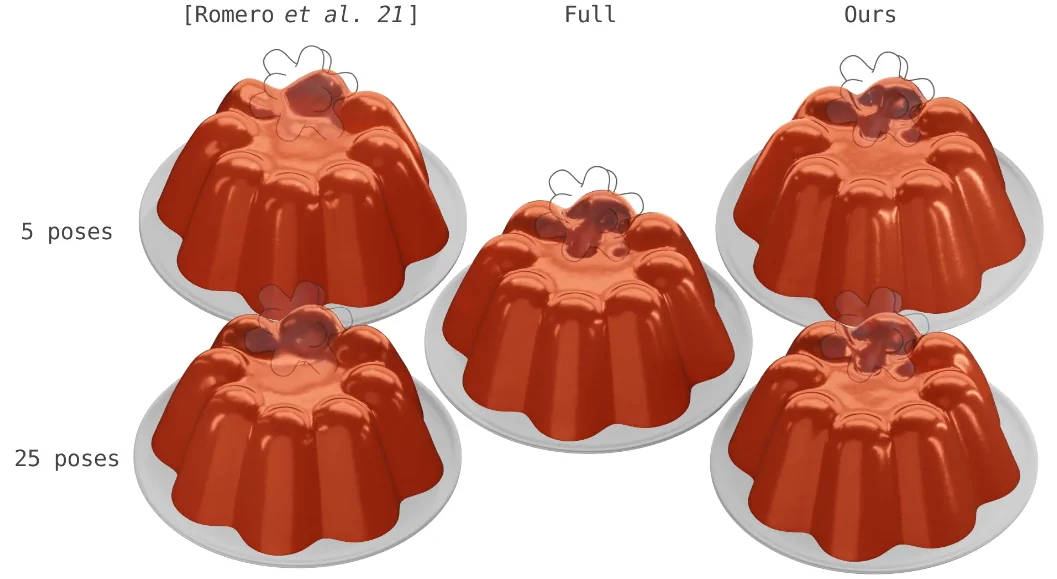
En la imagen anterior, nuestro enfoque mejora significativamente las capacidades de generalización del método de vanguardia del profesor Romero; y se acerca mucho al realismo de la simulación completa.
Nuestro método es capaz de aprender la compleja interacción entre el colisionador en forma de estrella; y la gelatina deformable utilizando un orden de magnitud menos de neuronas; y datos de entrenamiento que la configuración original utilizada por Romero.
Por el contrario, cuando se entrena con un conjunto de datos tan reducido no pueden aprender deformaciones; debido al contacto sobre puntos en el volumen del objeto deformable 𝑋.
El otro término es el error L2 de las diferencias de los desplazamientos de contacto estimados. Frente a las diferencias de los desplazamientos de entrenamiento reales, trabajando sobre los bordes de la superficie de 𝑋. Observamos una mejor conservación de los detalles de contacto al combinar ambos términos de pérdida.
Muestreo de la función de desplazamiento de contacto
La generación de datos de entrenamiento requiere muestrear los argumentos de 𝑓. Es decir, el espacio del colisionador, 𝑧¯, y la configuración relativa entre el objeto y el colisionador, T(z)−1 · x. Muestrear el espacio del colisionador es fácil.
Motivados por la función de pérdida definida anteriormente, usamos los nodos {𝑥¯𝑖} de la malla volumétrica del objeto deformable; y los transformamos al espacio colisionador mediante T(𝑧)−1 · 𝑥˜(𝑥¯𝑖). Tenga en cuenta que las muestras del espacio del colisionador varían según la configuración relativa del objeto deformable y el colisionador.
Muestrear la configuración relativa entre el objeto y el colisionador es más desafiante. La dimensionalidad de este espacio puede verse como el número de grados de libertad del objeto deformable, dejando fijo el colisionador. Sin embargo, bajo este punto de vista, el espacio sería muy difícil de muestrear, ya que solo nos preocupamos por las configuraciones en colisión.
Alternativamente, vemos el espacio como el producto cartesiano de cuatro subespacios: la configuración X del objeto deformable 𝑋; después de eliminar las transformaciones rígidas, la superficie del objeto deformable 𝜕𝑋 que define las ubicaciones de contacto; la rotación SO(3) del colisionador , y la profundidad de penetración D ⊂ R entre el colisionador y el objeto deformable.
Representación del espacio completo
El espacio completo se puede representar como X × 𝜕𝑋 × SO(3) × D. Muestreamos cada uno de estos cuatro subespacios de forma independiente. Para la profundidad de penetración, simplemente usamos muestras distribuidas uniformemente hasta una profundidad máxima, con un poco de ruido aleatorio.
Para los otros tres subespacios, generamos un gran conjunto potencial de muestras y elegimos un subconjunto representativo usando una estrategia de punto más lejano codicioso; basado en la distancia geodésica superficial para 𝜕𝑋 y la norma del ángulo del eje para 𝑆𝑂(3).
Prestamos especial atención al muestreo de la configuración libre de rigidez X del objeto deformable. Comenzamos ejecutando simulaciones de contacto interactivas entre el objeto deformable y el colisionador, aprovechando la velocidad del modelo de simulación subespacial del objeto deformable.
Para representar el espacio X de configuración libre de rigidez, construimos un gráfico de la conectividad del asa del modelo del subespacio; y para cada estado x del objeto deformable calculamos las transformaciones relativas del asa para todos los bordes del gráfico.
Distancia euclidiana entre transformaciones
Dado un conjunto de datos de transformaciones relativas, normalizamos por separado las entradas correspondientes a cada borde. Con base en esta definición de configuraciones sin rigidez; para la selección del punto más lejano usamos la distancia euclidiana entre las transformaciones de borde normalizadas.
Gracias a la suavidad de los desplazamientos de contacto del colisionador-espacio, junto con nuestra descomposición de la configuración relativa entre el objeto y el colisionador. Y la selección de la muestra del punto más lejano discutida anteriormente, logramos reducir drásticamente la cantidad de muestras necesarias en X, la configuración del objeto deformable.
Podría decirse que este es el subespacio más difícil de muestrear, y una estrategia de aprendizaje ingenua requeriría una exploración exhaustiva del espacio de configuración. En cambio, como se muestra en nuestros resultados en la sección 6 de este artículo. Muestreamos espacios complejos de configuración de alta dimensión (29 puntos de control en el pato) con menos de 10 muestras de configuración. Sin embargo, el modelo de aprendizaje se generaliza bien a estados no visibles.
Desplazamientos por contacto con el suelo o superficie
Usando el procedimiento descrito anteriormente, podemos muestrear configuraciones de contacto representativas del colisionador y el objeto deformable de manera eficiente. A continuación, para cada una de estas configuraciones debemos calcular los desplazamientos de contacto reales del suelo 𝑟 (𝑧¯). Como la diferencia entre las deformaciones de espacio completo 𝑥(𝑥¯) y las deformaciones del subespacio 𝑥˜(𝑥¯). Sin embargo, es importante que los estados del subespacio x de estos campos de deformación coincidan.
La deformación del subespacio está dada directamente por la generación interactiva de configuraciones de contacto. Por lo tanto, nos queda calcular una deformación de espacio completo restringida al mismo estado subespacial.
Aunque esta tarea es parte del preproceso, una solución típica de dinámica restringida basada en multiplicadores de Lagrange podría llevar mucho tiempo; debido a la gran cantidad de simulaciones y al tamaño de la representación de espacio completo. En cambio, restringimos la simulación de espacio completo al espacio nulo del subespacio usando un método de proyección. 𝑇 −1

La factorización de Cholesky
Dada la base U del subespacio, la matriz P = I−U U U U𝑇 representa una proyección al espacio nulo del subespacio. Para ejecutar la simulación de espacio completo, usamos el método de gradiente conjugado modificado, siendo P la matriz de proyección. Debemos tener en cuenta que no calculamos explícitamente P, solo calculamos la factorización de Cholesky de U𝑇 U; que es pequeña y rápida, y aplicamos las diversas multiplicaciones de matrices en cada iteración del gradiente conjugado.
En la imagen anterior vemos las capacidades de generalización de nuestro método centrado en el colisionador también son evidentes en este ejemplo de gelatina 3D. Nuestro método es preciso cuando se entrena con solo 5 poses de gelatina, y aumentar el número de poses a 25 proporciona poca ganancia.
Por el contrario, el aprendizaje centrado en objetos, como el realizado por Romero en el 2021; no logra aprender las deformaciones de contacto con 5 poses y solo mejora ligeramente con 25 poses. En la Tabla 2 proporcionamos comparaciones numéricas. El aprendizaje centrado en objetos sufre la maldición de la dimensionalidad y requeriría una cantidad intratable de poses de entrenamiento.
Simulación de deformaciones dinámicas
Nuestras novedosas deformaciones aprendidas centradas en el contacto se pueden agregar a un modelo de simulación subespacial dinámica. Conservando la formulación subespacial rápida en la simulación combinada. En esta sección, formulamos el problema de dinámica completa; prestando especial atención a la inclusión de la función de desplazamiento de contacto basada en el aprendizaje 𝑓 en (4).
Encontramos conveniente formular la dinámica como un problema de optimización, utilizando la formulación de optimización de Euler hacia atrás. De esta manera, podemos usar sin problemas nuestras definiciones de campo de deformación; integrar cantidades en el espacio completo y optimizar solo los grados de libertad del subespacio. Dada una configuración de colisionador z y una actualización explícita de Euler de las posiciones de espacio completo 𝑥∗(𝑥¯); la configuración del subespacio del objeto deformable se calcula como sigue:
- x = arg min𝑊inertial +𝑊elastic +𝑊contact
- 𝑊inertial =∫𝑋𝜌2ℎ2∥𝑥 (𝑥,¯ x, z) − 𝑥∗(𝑥¯) ∥2𝑑𝑥
- 𝑊elastic =∫𝑋Ψ(𝑥 (𝑥,¯ x, z)) 𝑑𝑥
- 𝑊contact =∫𝜕𝑋Φ(T(z)−1· 𝑥 (𝑥,¯ x, z)) 𝑑
Aquí, 𝜌 es la densidad de masa del objeto, ℎ es el paso de tiempo y el campo de deformación de espacio completo 𝑥 (𝑥¯) se define combinando.
Dependencias implícitas de los objetos deformables
En esta expresión, mostramos las dependencias explícitas de la configuración del objeto deformable x, ya que son importantes para la evaluación de gradientes. Ψ es un modelo de energía elástica. En nuestro caso, hemos utilizado la formulación Neo-Hookean estable. Φ es un potencial de contacto basado en un campo de distancia con signo pre-calculado para el colisionador.
Es cero para distancias negativas y cúbico para distancias positivas. Integramos los términos inercial y elástico usando curvatura, con puntos de curvatura y pesos aproximados utilizando un enfoque de ignorar algunos datos. En su lugar, integramos el término de contacto utilizando todos los puntos de malla de la superficie.
Para resolver la optimización, usamos un solucionador Newton-CG. Para 𝜕𝑓 evaluamos los gradientes de la función de aprendizaje 𝜕x , realizamos retro-propagación en la red neuronal. No almacenamos el hessiano explícitamente, sino que ejecutamos productos vectoriales hessianos. En este sentido, ignoramos el hessiano de la función de aprendizaje; e implementamos productos de vector de gradiente a través de un paso de retro-propagación auxiliar.
A pesar del pequeño tamaño del hessiano subespacial, encontramos más conveniente usar Newton-CG que un solucionador directo. Ya que cada paso de Newton requería muy pocas iteraciones de CG en la práctica y; por lo tanto, minimizaba el número de evaluaciones de red.
Resultados de esta deformación dinámica del objeto por contacto
En esta sección evaluamos cuantitativa y cualitativamente nuestro método en una variedad de objetos, escenarios e interacciones. Además, lo comparamos con el método de vanguardia de Romero, quienes también modelan deformaciones de contacto utilizando un enfoque basado en datos.
Como referencia, también mostramos los resultados utilizando un modelo de subespacio lineal basado en Wang. Todos los ejemplos se ejecutaron en un PC Intel Core i7-7700K de 4 núcleos a 4,20 GHz con 32 GB de RAM.
En la tabla que puedes ver en el PDF proporcionamos detalles de los objetos y conjuntos de datos utilizados para generar nuestros resultados. Incluida la discretización de malla de las simulaciones de espacio completo.
La imagen 5 muestra fotogramas de un colisionador en forma de estrella interactuando con una gelatina 2D; utilizando 4 métodos diferentes: simulación completa, nuestro enfoque centrado en el contacto, el método de vanguardia de Romero, y el método lineal de Wang.
Código disponible al público
Debemos tener en cuenta que utilizamos el conjunto de datos original y el código disponible públicamente de Romero. Pero, para enfatizar las posibilidades de generalización de nuestro enfoque, utilizamos una versión reducida del conjunto de datos, que consta de 16.800 muestras reales (≈ 15 veces menos que su conjunto de datos).
Para evaluar cuantitativamente nuestros resultados, también trazamos el error medio por vértice de cada método a través de una secuencia de prueba de más de 2000 fotogramas. Nótese, además, que nuestro modelo requiere solo 300 neuronas, mientras que método de Romero requieren 3.000 neuronas.
La imagen 6 muestra una comparación similar en 3D, con un colisionador puntiagudo interactuando con una gelatina 3D. Demostramos que nuestro enfoque de aprendizaje colidercéntrico es preciso cuando se entrena con solo 5 configuraciones de la gelatina.
El coste de entrenamiento está dominado por la simulación de todas las muestras de entrenamiento (48.000 en total. Teniendo en cuenta todas las configuraciones muestreadas del colisionador), que llevó 37 horas. Con los mismos datos de entrenamiento, el aprendizaje centrado en objetos de Romero no produce resultados precisos.

Aprendizaje automático centrado en objetos
El aprendizaje centrado en objetos sufre la maldición de la dimensionalidad; y multiplicar los datos de entrenamiento a 25 configuraciones de la gelatina (184 horas) apenas mejoró los resultados. Los errores para todas las configuraciones también se comparan numéricamente en la tabla 2 del PDF.
Los ejemplos de prueba se generaron proyectando deformaciones estáticas de espacio completo en el subespacio; basado en manijas y luego agregando deformaciones de contacto basadas en aprendizaje. Los errores se normalizan con respecto a la diferencia entre la deformación del subespacio lineal y del espacio completo.
Estos resultados muestran que, cuando se usa la misma cantidad de datos de entrenamiento; nuestro método generaliza mucho mejor que el enfoque de vanguardia del proyecto Romero. Y reproduce fielmente el realismo de una simulación completa.
Es importante destacar que nuestro método no solo puede entrenar con menos datos; sino también modelar interacciones de contacto más complejas y altamente deformables a velocidades de cuadro en tiempo real.
El error relativo para los diferentes métodos y configuraciones de entrenamiento del ejemplo 3D Jelly; que se muestra en la imagen 6 lo podemos ver desglosado en la tabla 2 del PDF.
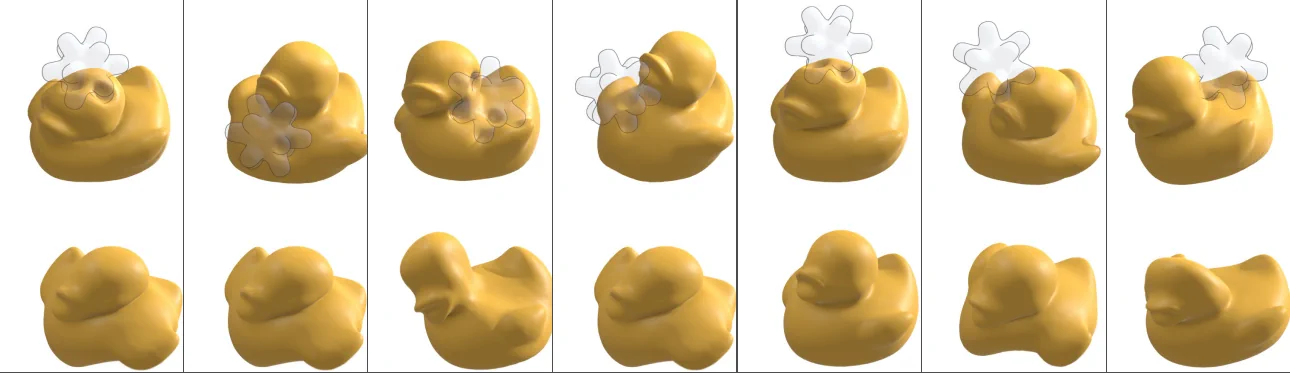
Evaluación cualitativa de la deformación dinámica del objeto por contacto
En la imagen 7 de evaluación cualitativa. Mostramos 4 fotogramas de una secuencia donde un colisionador (semitransparente, para una mejor visualización) interactúa con un patito de goma. Nuestro método (centro) coincide estrechamente con las deformaciones naturales debidas al contacto que emergen utilizando un modelo de simulación completo (izquierda).
Por el contrario, un modelo lineal Wang no puede deformarse correctamente. Hemos utilizado el gusano en las imágenes 3 y 4 para evaluar el efecto cualitativo y cuantitativo de la dispersión. en la tabla 3 del PDF podemos ver el error relativo en el ejemplo de Worm; con y sin dispersión, para diferentes cantidades de datos de entrenamiento.
En la imagen 8. Para representar las buenas posibilidades de generalización de nuestro método; aquí visualizamos la muestra de entrenamiento más cercana (abajo) a una amplia gama de diferentes estados del pato deformable (arriba).
Los fotogramas se eligieron al azar de una secuencia en la que el colisionador interactúa en tiempo real con el pato. Para esta demostración en particular, usamos solo 8 muestras del estado X del pato para entrenar el sistema. Dado que nuestro enfoque está centrado en el colisionador, se generaliza bien a estados invisibles del pato deformable.
Función de aprendizaje en la deformación dinámica del objeto por contacto
Hemos comparado el error con respecto a una simulación de espacio completo, con y sin expansión; para diferentes cantidades de datos de entrenamiento (variando las muestras del espacio de configuración del gusano). Los errores informados en la tabla 3 del PDF confirman que la dispersión permite una reducción drástica en la cantidad de datos de entrenamiento requeridos.
Mano. La imagen 1 y el video complementario muestran una secuencia interactiva en la que una mano en 3D manipula un cubo rígido. La deformación del subespacio se construye con el modelo MANO del proyecto Romero, y el esqueleto se simula dinámicamente.
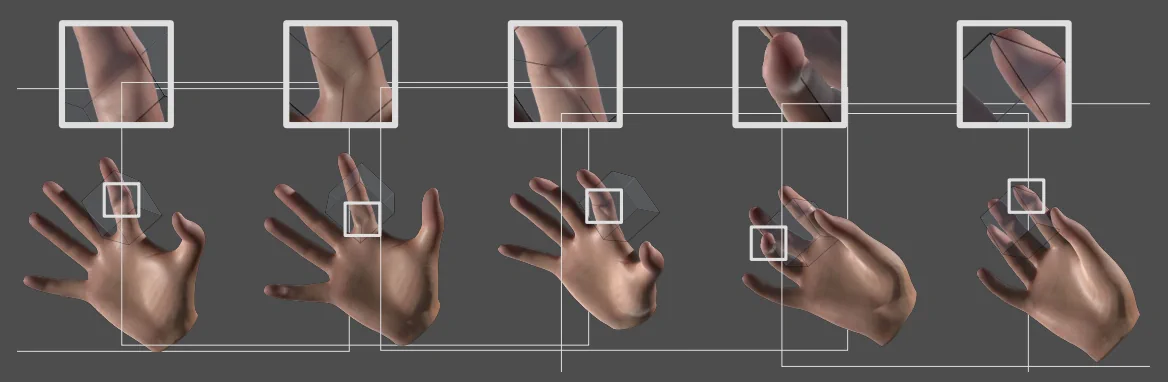
La interacción en tiempo de ejecución se produjo de forma interactiva con un dispositivo LeapMotion. Para el seguimiento de la mano y el control del esqueleto de la mano a través de fuerzas de resorte. Observa cómo la superficie de la piel de la mano se deforma naturalmente cuando toca el cubo; incluso en bordes y esquinas afiladas, todo en tiempo real.
Este ejemplo fue entrenado en una única pose plana de la mano. A pesar de un muestreo tan extremadamente simple del espacio de configuración de la mano; nuestra formulación centrada en el contacto. Junto con los pesos dispersos, logran una excelente generalización a las poses de manos invisibles.
Precisión comprobada en la deformación dinámica del objeto por contacto
Demostramos que la precisión de la deformación por contacto está bien mantenida en todas las regiones de la mano. Incluidas la palma y la punta de los dedos, y para cualquier pose de la mano.
La imagen 7 muestra fotogramas de una secuencia en la que un colisionador interactúa estrechamente con un patito de goma. Esta compara cualitativamente nuestros resultados con las deformaciones obtenidas con un modelo subespacial lineal realizado por Wang; y una simulación de espacio completo.
El modelo lineal, acotado por la limitada expresividad del subespacio, es incapaz de reproducir las deformaciones debidas al contacto, produciendo un comportamiento antinatural. Por el contrario, nuestro enfoque es capaz de modelar con precisión las deformaciones debidas al contacto. Igualando de cerca el realismo de la simulación de espacio completo, incluso en situaciones con interacciones fuertes y estados muy deformados. Consulta el video complementario para ver los resultados animados, dejamos el video al final del artículo.
En la imagen 8, para evaluar cualitativamente las capacidades de generalización de nuestro enfoque; mostramos fotogramas de una secuencia en la que manipulamos interactivamente el pato con un colisionador. Para cada cuadro, mostramos la deformación de pato más cercana en el conjunto de entrenamiento.
Nuestro método puede reproducir con precisión las deformaciones
Ten en cuenta que, incluso cuando la muestra más cercana está lejos del estado actual del pato; nuestro método puede reproducir con precisión las deformaciones debidas al contacto. En el caso particular del escenario del Pato; nuestra representación centrada en el contacto es capaz de aprender un contacto preciso con un objeto deformable usando tan solo 8 ejemplos deformados.
Es importante destacar que, incluso si aprendemos deformaciones sin dinámica o fricción, en tiempo de ejecución nuestro método se generaliza bien a esas configuraciones.
Nuestro método no se basa explícitamente en las características geométricas del objeto deformable o del colisionador, como el género o las simetrías. La imagen 9 muestra una escena con un flotador deformable de género 1 y un colisionador de proyectiles.
El flotador cae encima del caparazón y se deforma para dejar pasar el caparazón. Con un método de subespacio lineal, el caparazón no pasa a través del flotador, ya que las deformaciones necesarias no están bien representadas. Nuestro método, por otro lado, los representa correctamente.
Conclusiones y trabajo futuro
En este trabajo, hemos presentado un método centrado en el contacto para aprender deformaciones impulsadas por el contacto. Estas deformaciones se agregan a un modelo de simulación dinámica subespacial; para producir simulaciones dinámicas en tiempo real de objetos deformables con gran detalle de contacto.
Hemos demostrado que la parametrización centrada en el contacto de la función de aprendizaje simplifica drásticamente su complejidad; el espacio de configuraciones puede muestrearse escasamente y los modelos de aprendizaje automático resultantes son más pequeños; más eficientes y más fáciles de aprender.
Complementamos aún más el modelado centrado en el contacto con una representación de campo continua y dispersión de la función de aprendizaje; que contribuyen a una excelente capacidad de generalización.
Nuestro trabajo no está libre de limitaciones, y algunas de ellas sugieren direcciones para trabajos futuros no triviales. Aprendemos un modelo de deformación por objeto colisionador. Esto podría tener aplicabilidad en aplicaciones interactivas en las que los colisionadores se conocen de antemano. Pero no aborda las aplicaciones en las que múltiples colisionadores interactúan de formas complejas o en las que los colisionadores se definen dinámicamente.

Colisionador rígido en la deformación dinámica del objeto por contacto
También asumimos que el colisionador es rígido, lo que nuevamente cubre un gran conjunto de casos de uso. Pero no tiene en cuenta el contacto deformación a causa de otra deformación.
Un flotador de espacio completo (izquierda) cae sobre un caparazón rígido y se deforma para dejar pasar el caparazón. Este movimiento está bien representado con nuestro método (centro), mientras que un subespacio lineal (derecha) no representa las deformaciones necesarias y la cubierta se atasca.
Hemos introducido nuestro enfoque de modelado centrado en el contacto en el contexto de la simulación de objetos deformables. Sin embargo, este enfoque podría encontrar aplicabilidad en otros problemas de interacción con objetos. Como el seguimiento conjunto de manos y objetos, o la síntesis de agarre.
Nuestro agradecimiento a las referencias y ayudas
Deseamos agradecer a los revisores anónimos por sus útiles comentarios. También agradecemos a Mickeal Verschoor y Suzanne Sorli por su ayuda con la demostración manual. Este trabajo fue financiado en parte por el Consejo Europeo de Investigación.
Puedes descargar el PDF original creado por los siguientes profesores e investigadores del campo gráfico relacionado con el aprendizaje automático; Cristian Romero, Dan Casas y Miguel A. Otaduy, los tres de la Universidad Rey Juan Carlos en España; y un cuarto profesor; Maurizio M. Chiaramonte de Meta Reality Labs Research en USA. Puedes acceder a su página web aquí.

Hasta aquí este artículo sobre la deformación dinámica del objeto por contacto, puedes ver más información y comentarios en el foro, sigue leyendo…